All’alba del 2014 mi capita ancora troppe volte di vedere account strutturati in maniera tutt’altro che ottimale. E se da un lato posso essere d’accordo che spesso non è facile ricominciare da zero con un account pulito e ristrutturato, dall’altro ci sono tante ottime ragioni per farlo, e tante tecnologie e soluzioni per facilitarlo. In questo post vedremo cosa è e perché accade il fenomeno del campionamento dei dati, perché le soluzioni adottate in passato non sono più ottimali e come si ovvia al giorno d’oggi.
Campionamento 101: di cosa si parla
Il fenomeno del campionamento (box giallo in alto a destra) avviene ogni volta che si chiede a Google Analytics di produrre dati che non sono precalcolati nei report standard. Ho descritto in passato cosa accade e perché nei due post “come funziona il campionamento” e “come funziona il campionamento (ufficiale)“, che ti invito a ripassare prima di proseguire nella lettura.
Per quanto concerne questo post, la parte fondamentale di quei due articoli è quella che dice “E’ importante notare che il campionamento avviene a livello di web property e non di profilo” (oggi i profili si chiamano “viste”). Avere delle viste-copia non risolve il problema del campionamento, se la vista principale conta tantissime visite.
Il fittizio caso esempio
Il famoso brand ACME è una multinazionale globale, con sedi in tutto il mondo e 30 siti in lingua attestati su 30 diversi top level domain. Per le sue esigenze di marketing interne ha bisogno di KPI a livello globale (rollup) e insight a livello di singola country/lingua.
Fino a qualche tempo fa l’approccio standard era: traccio tutto con una unica web property su GA, quindi con un solo UA, poi creo 30 viste-copia e su ognuna metto un filtro sul nome host.
Questa soluzione si portava appresso alcuni assunti e alcuni accorgimenti da prendere: se il visitatore può passare da un dominio all’altro (ad esempio perché cambia lingua, o perché il sito worldwide ha una spashpage con selezione lingua, o perché il gateway di pagamento ecommerce è uno solo in tutto il mondo ed è attestato in un sottodominio del sito .com, o per qualsiasi altro motivo…) è necessario impostare correttamente il cross domain tracking, altrimenti i conteggi di visite e visitatori unici nel profilo di rollup saranno gonfiati. Inoltre se non si gestisce il passaggio dei cookies, il profilo di rollup vedrà moltissime visite con referral interni (quando un utente passa dal .it al .de diventa un nuovo utente unico, si crea una nuova visita e la sorgente di traffico è un sito ACME). Idem i profili clone, che in assenza del cross domain tracking non conservano la sorgente di traffico originale, ma sono funestati dal fenomeno self referral.
Anche ammesso che questa parte sia stata gestita a puntino, il tutto subirà i nefasti effetti del campionamento se il profilo di rollup salirà molto con le visite. Nel caso in cui il rollup registri 5 milioni di visite, anche una vista copia per un paese nel medesimo periodo segna solo 60 mila visite subirà un campionamento al 5%, perché quando Analytics campiona ritorna sempre ai dati della property per estrarre il campione, e poi rifiltra il risultato secondo le regole impostate nella vista.
Come si riduce, oggi, questo fenomeno?
Oggi non mi sogno più di consigliare le viste clone in casi come questo, gli svantaggi sono evidenti sia in termini di manutenzione (decine o centinaia di filtri da tenere d’occhio) sia soprattutto in termini di performance.
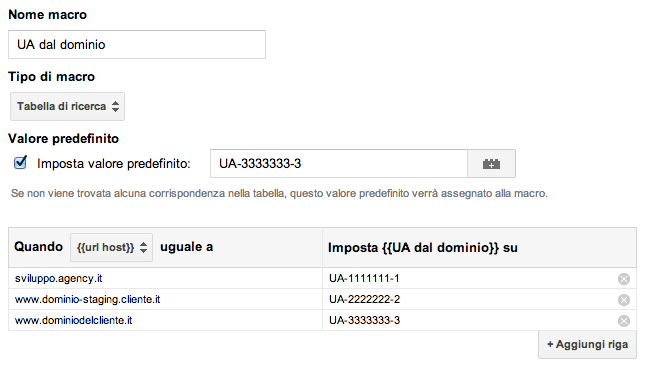
Oggi, grazie soprattutto all’avvento delle tecnologie di Tag Management (ma non è obbligatorio) e di Universal Analytics (soprattutto per quanto riguarda la parte di cross domain tracking) l’approccio che consiglio è quello di “una web property per ogni cosa”:
- Profilo di rollup? una web property! UA-xxxxxx-1
- AMCE.it? una web property! UA-xxxxxx-2
- ACME.de? una web property! UA-xxxxxx-3
- ecommerce globale? una web property! UA-xxxxxx-4
- e così via…
Ovviamente su ogni pagina del sito ci saranno almeno due codici di monitoraggio (il rollup e il singolo dominio, ma potrebbero esserci anche codici per singoli sottoprogetti, non c’è limite alla fantasia…), il cross domain tracking deve essere impeccabile, e per fare queste due cose con semplicità io consiglio l’uso del Google Tag Manager; ma una volta messo in piedi il sistema, i risultati sono garantiti: il numero di visite è sempre congruente tra le property, sebbene non si possa sommare per ovvi motivi. Se passo dal it. al .de sono 1 visita su ognuna delle viste, ma sono 1 sola nel rollup. La sorgente di traffico è sempre quella originale che ha portato l’utente sui siti, e raramente è un referral interno. Ma soprattutto il campionamento viene eseguito sulla base dei reali dati di traffico: con gli stessi numeri dell’esempio precedente il profilo di rollup subisce un campionamento al 5%, ma il profilo con 600 mila visite lo subisce solo al 41%.
Inoltre ogni web property può essere usata singolarmente per produrre viste clone filtrate, su base dominio e non su base rollup. Il che a me sembra un ulteriore vantaggio!