Apr 03 2024



Il salto dello squalo di Google Analytics?

Ci si riferisce al “salto dello squalo” come al punto di svolta (che vira in negativo) della carriera o della storia di qualcosa, sulla scia della famosa (o famigerata) prima puntata della quinta serie di Happy Days in cui Fonzie sugli sci d’acqua salta, appunto, sopra uno squalo.
Ora, è ovvio che il titolo è volutamente pompato, d’altronde sono mesi che non scrivo e in qualche modo devo farvi tornare :D, però nelle ultime settimane sono successe due cose troppo grosse e troppo vicine tra loro per non far storcere il naso anche ai fan di più vecchia data come il sottoscritto. A cosa mi riferisco?
Primo, di minore entità per le persone “normali” ma di grande impatto per i grossi brand che ancora utilizzano Universal Analytics (e si, ce ne sono ancora, e si, ne hanno il diritto perché pagano, e nemmeno poco). Come sanno anche i sassi il 6 marzo è entrato in vigore il DMA, e alcune feature di Universal Analytics sono state deprecate anzitempo, diversamente da quanto in precedenza comunicato. Qui le parole chiave sono “deprecate anzitempo”, “diversamente” e “precedentemente comunicato”.
Si perché uno si aspetta che certe comunicazioni di impatto piuttosto grande vengano fatte con largo anticipo, specie ai clienti paganti, in modo che si preparino per bene. E invece no: nell’elenco delle deprecazioni, vi agevolo il link per comodità, troviamo (tra le altre) cose come “scomparsa dei report demografici e sugli interessi” (capisco, sono basati su dati Google, ci sta), “import dei dati SalesForce” (paura che si importino dati personali? può essere), “fine dell’export intra-day su BigQuery” (ma perché?), “deprecazione degli identificativi ad click come gclid e dclid” (beh si in effettWAIT! COSA?? COSA HAI DETTO?)
E quindi, dal 6 marzo il gclid è come se non esistesse, e Google consiglia di mettere gli UTM sulle campagne GADS e Doubleclick. Certo, come se anche le più scafate agenzie media worldwide fossero tutte in grado di sapere che bisogna smanettare con Ads Script per avere il nome della campagna, che di default non esiste come ValueTrack… come se pochi giorni di tempo fossero sufficienti a modificare tutto. Esatto, perché stiamo parlando esattamente di QUANDO Google l’ha detto? Se siano girate email non lo so, ma siccome due o tre casi direttamente o indirettamente li ho visti e un paio di forward di mail di personale Google li ho letti, diciamo che non l’hanno detto con mesi di anticipo. Ma restiamo sull’ufficiale, la famosa pagina della transizione. Ecco qua INTERNET ARCHIVE interrogato all’uopo:
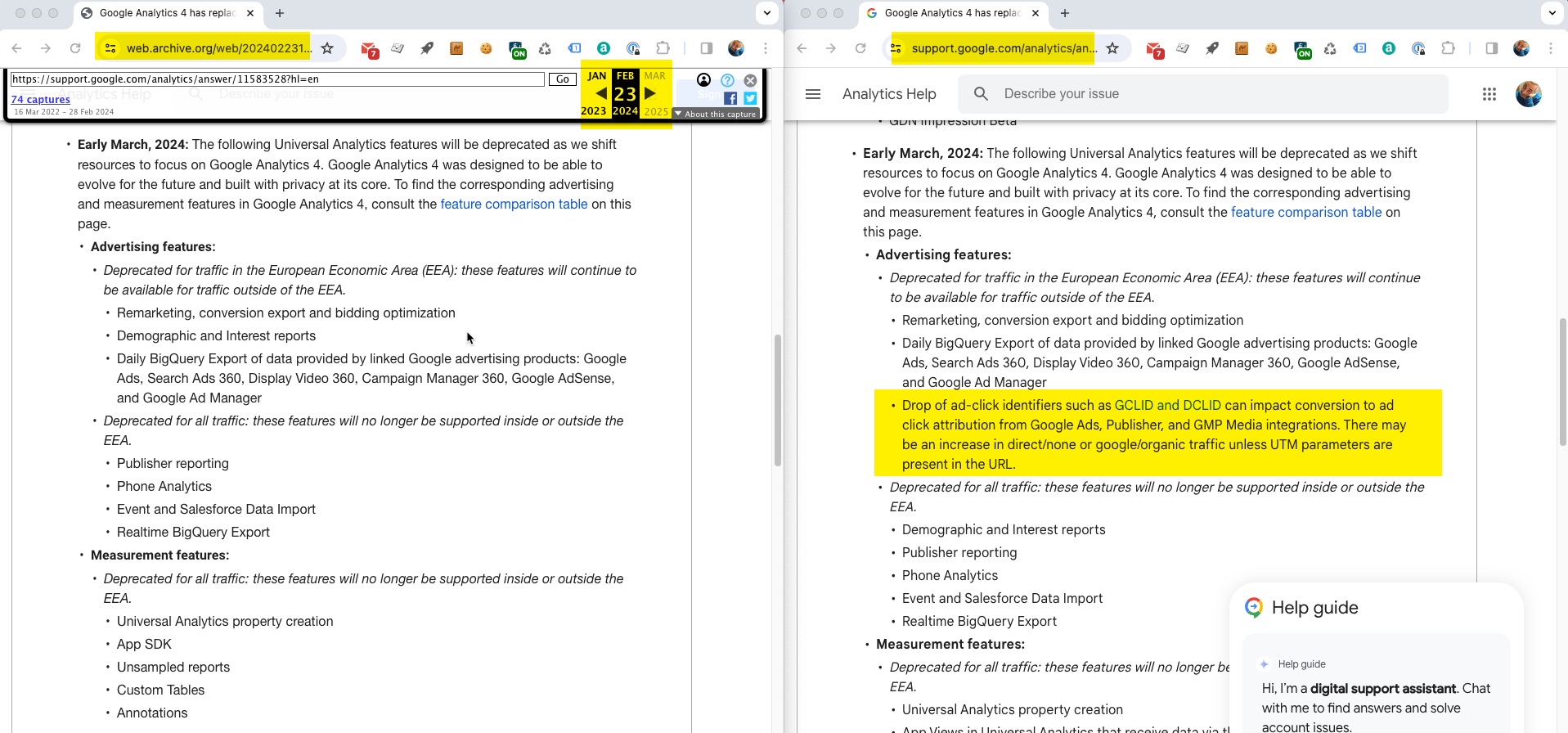
il 23 febbraio la pagina ufficiale della transizione non menziona la scomparsa del GCLID, il 5 marzo si. Non ci sono snapshot di mezzo, quindi col beneficio del dubbio diciamo che l’hanno detto con non più di 14 giorni di anticipo. No anzi, l’hanno pubblicato. Poi sta a noi fare refresh di quella pagina una volta al giorno, ovviamente.
Secondo, lo spostamento del report Google Ads nella sezione ADVERTISING di Google Analytics 4, di per sé nulla di male se non che:
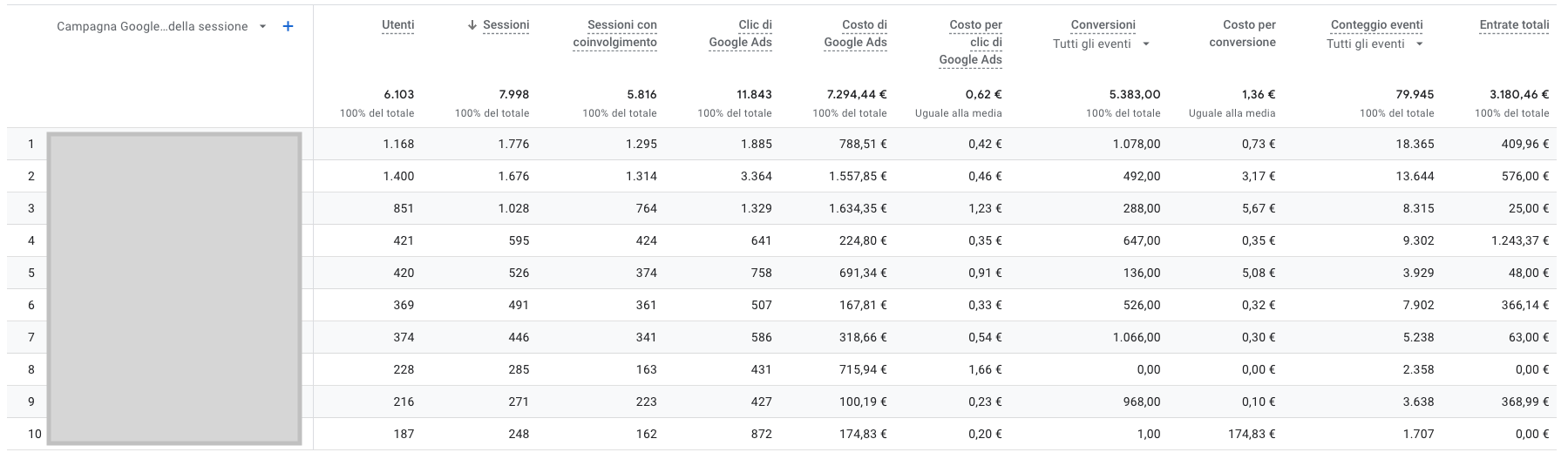
- nella sezione advertising non posso creare e modificare report, quindi mi prendo quel che c’è. E quel che c’è è MOLTO MENO di quel che c’era nel report “vecchio” nella sezione dei report. Nel “nuovo” report ci trovo solo Conversioni, Costo, Costo per Conversione, Click, CPC, Revenue e ROAS. Sessioni? no. Eventi? nemmeno. Engagement/Bounce? non pervenuti.
- I report della sezione advertising seguono l’impostazione di attribuzione che c’è nell’admin, quindi DATA DRIVEN o LAST CLICK (data driven di default). Se non lo so, rischio di non capire quel che leggo. E qualcuno potrebbe anche cambiare il setting da un giorno all’altro.
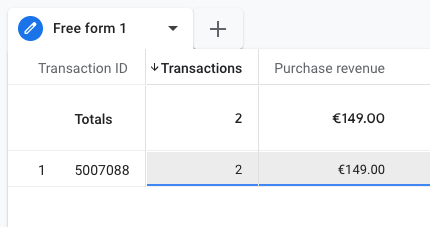
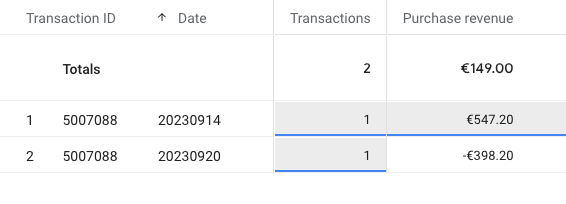
- Google ha CAMBIATO il vecchio report, eliminando le metriche di preclick. Il “nuovo vecchio” report ha le informazioni sul post click e basta. SE siete fortunati il vecchio report ve lo eravate salvati come una copia nella libreria dei report, e quello non lo toccano (o almeno, su alcuni clienti s’è salvato). Mi riferisco al report con queste colonne

- Se provo a ricreare un report mischiando metriche di pre e post click… non posso. Non è permesso! nella costruzione del report standard semplicemente NON CI SONO le metriche di GADS. Posso sempre fare un explorer, certo, ma non è la stessa cosa. Ma soprattutto PERCHÉ? perché limitare così la possibilità di vedere i dati delle campagne?

In buona sostanza abbiamo un Google che toglie, toglie funzionalità dal giorno alla notte e toglie possibilità, senza vedere dall’altra parte un Google che da qualcosa in cambio, almeno per ora. Magari poi quando spengono le macchine su cui gira Universal e le aggiungono ai datacenter di GA4 ci stupiscono, ma per adesso speriamo nel cliffhanger di fine stagione.